Customizing Asent#
![]()
Asent is built using a series of extension attributes on the spaCy
classes, Doc, Token and Span. This allows you to switch
out the parts and also improve on one component at a time. In this
tutorial, we will move you through how to customize your own pipeline.
This will first include a quick approach using the Asent
component to implement a Swedish pipeline. Then we will customize
the way the pipeline checks if a word is negated.
To read more about the custom spaCy extensions check out their documentation.
Before we start we will need a spaCy pipeline for Swedish. Here we will use the experimental version which you can install using:
# this can take a while
pip install https://huggingface.co/explosion/sv_udv25_swedishtalbanken_trf/resolve/main/sv_udv25_swedishtalbanken_trf-any-py3-none-any.whl
Which can then be loading using spaCy:
import spacy
nlp = spacy.load("sv_udv25_swedishtalbanken_trf")
Attention
This pipeline requires a GPU and torch>=1.9.0
See also
If you don’t wish to use the experimental version by spaCy we recommend pipeline by the Swedish royal library.
Creating the pipeline#
A large part of the customization is made simple using the Asent
component. Here we will implement the Swedish Asent pipeline, for
this we need a dictionary of rated words and potentially a list of
intensifiers, negation and contrastive conjunctions.
We can extract these using the lexicons.get function:
from asent import lexicons
rated_words = lexicons.get("lexicon_se_v1")
negations = lexicons.get("negations_se_v1")
intensifiers = lexicons.get("intensifiers_se_v1")
Before we move on let us check what each of these contains, let us
start with the rated_words, this is a dictionary which contain
words as well as a human rating of how positive/negative it is:
list(rated_words.items())[140:150] # the start of the dictionary is mostly emoticons
[('motbjudande', -3.1),
('avskyr', -2.9),
('förmågor', 1.0),
('förmåga', 1.3),
('ombord', 0.1),
('frånvarande', -1.1),
('frikänna', 1.6),
('befrias', 1.5),
('frikänner', 1.6),
('missbruk', -3.2)]
negations is simply a list or a set of words, which is considered
negations:
list(negations)[:10]
['utan',
'aldrig',
'ingenting',
'sällan',
'trots',
'ingenstans',
'ingen',
'nej',
'varken',
'inte']
Finally, intensifiers is a dictionary of words such intensifies
the valence of another words (e.g. “very”). It is associated with a
score on how much it intensifies to the following word.
list(intensifiers.items())[:10]
[('absolut', 0.293),
('otroligt', 0.293),
('väldigt', 0.293),
('helt', 0.293),
('betydande', 0.293),
('betydligt', 0.293),
('bestämt', 0.293),
('djupt', 0.293),
('effing', 0.293),
('enorm', 0.293)]
We can now add a sentiment component to the pipeline, using the
Asent component:
import asent
from asent.component import Asent
Asent(
nlp, name="asent_se", lexicon=rated_words, intensifiers=intensifiers, negations=negations, lowercase=True, lemmatize=False
)
# test it out and visualize results
doc = nlp("Jag är enormt lycklig")
asent.visualize(doc)

Do note, that we specified that when the model should lookup in the
dictionaries it should lowercase the lookup word (lowercase=True)
and it should not lemmatize(lemmatize=False) the word. This
should naturally correspond to the lexicons you are using, if your
lexicon contains lemmas then you should lemmatize beforehand, if your
lexicon is case sensitive you should not lowercase before the look
up.
Customizing your Pipeline#
In the following, we will customize our pipeline a bit further. We will especially look at the negations. The current implementation based on Hutto and Gilbert (2014) assumed that the word is negated if one of the three proceeding words is a negation. This is a simplifying assumption which has been shown to generally work well, however, with spaCy performing a dependency parse and part-of-speech tagging we can do better!
Examining an example#
First let us examine an example where it fails:
doc = nlp("Jag är inte glad men jag skulle inte säga att jag är ledsen.")
# I am not happy but I would not say that I am sad.
asent.visualize(doc)
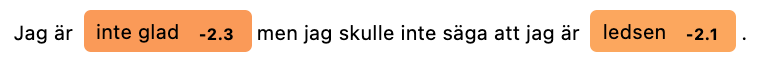
from spacy import displacy
# examine the part-of-speech tags and dependency tree
displacy.render(doc)
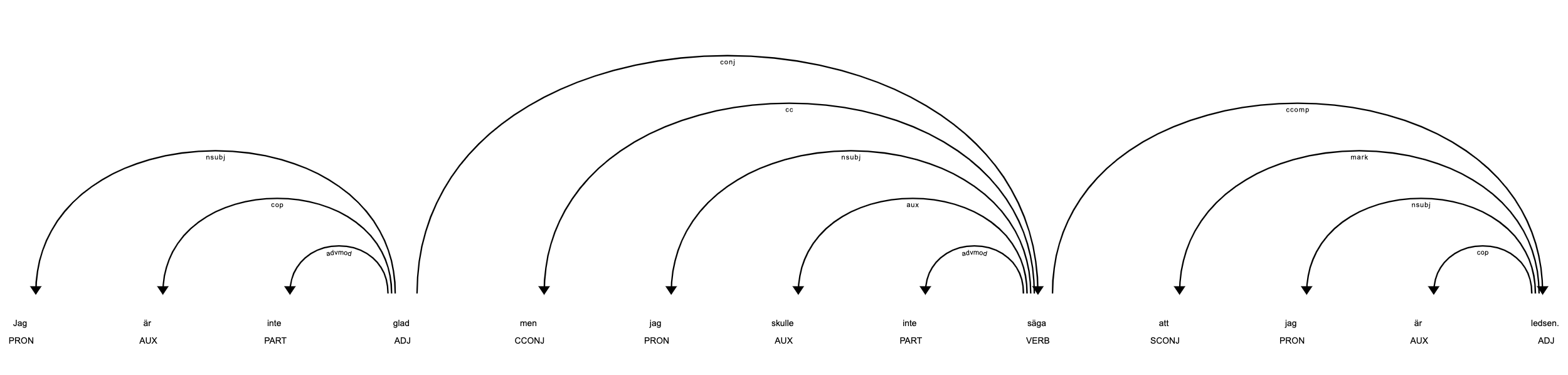
From this we can notice two things:
1) Negation have the PART part-of-speech tag, indicating that it is a particle, which among other things include negations.
2) Negations is related to other words using the advmod, and the words we wish negated is “down the tree” (or down the arrow if you will) from the negated word.
We can even go a bit further and examine the morph extension:
for t in doc:
print(t, "\t", t.morph)
Jag Case=Nom|Definite=Def|Gender=Com|Number=Sing|PronType=Prs
är Mood=Ind|Tense=Pres|VerbForm=Fin|Voice=Act
inte Polarity=Neg
glad Case=Nom|Definite=Ind|Degree=Pos|Gender=Com|Number=Sing
men
jag Case=Nom|Definite=Def|Gender=Com|Number=Sing|PronType=Prs
skulle Mood=Ind|Tense=Past|VerbForm=Fin|Voice=Act
inte Polarity=Neg
säga VerbForm=Inf|Voice=Act
att
jag Case=Nom|Definite=Def|Gender=Com|Number=Sing|PronType=Prs
är Mood=Ind|Tense=Pres|VerbForm=Fin|Voice=Act
ledsen Case=Nom|Definite=Ind|Gender=Com|Number=Sing|Tense=Past|VerbForm=Part
.
Where we see that the negation “inte” is denoted by Polarity=Neg, indicating that it is a negation.
from this, there are two things we can change, first instead of looking up the negation, we can examine whether it is a negation or at least that it has the right part-of-speech tag. Secondly, we can implement a method which check if a word is negated using the dependency tree.
Morphology and Part-of-Speech for negations#
Asent check is a word is a negation using the is_negation token
extension. We can see this using:
for t in doc:
print(t, "\t", t._.is_negation)
Jag False
är False
inte True
glad False
men False
jag False
skulle False
inte True
säga False
att False
jag False
är False
ledsen False
. False
We will now simply overwrite the extension with one using the morph
tag. First, we will create a function which applied to a token returns
whether it is a negation. Secondly, we will overwrite the extensions
using the token’s set_extention method.
from spacy.tokens import Token
def is_negation(token: Token) -> bool:
"""checks is token is a negation
Args:
token (Token): A spaCy token
Returns:
bool: a boolean indicating whether the token is a negation
"""
m_dict = token.morph.to_dict()
return ("Polarity" in m_dict # if is has the polarity attribute
and m_dict["Polarity"] == "Neg") # and it is negative
Token.set_extension("is_negation", getter=is_negation, force=True)
Now our negations use the morph tag, which in this case provides the same results so the result isn’t that interesting. What we really what it the second part:
Using the dependency tree for negations#
In the following, we will overwrite the is_negated extension used
by Asent to check if a word is negated. We can start by examining it:
for t in doc:
print(t, "\t", t._.is_negated)
Jag None
är None
inte None
glad inte
men inte
jag inte
skulle None
inte None
säga inte
att inte
jag inte
är None
ledsen None
. None
Noticably, see that ledsen is not negated, although it should be, but we also clearly see the three following words after the negation is negated as was expected from the heuristic rule.
from typing import Optional
def is_negated(token: Token) -> Optional[Token]:
"""checks is token is negated
Args:
token (Token): A spaCy token
Returns:
Optional[Token]: return the negation if the token is negated
"""
# only check if a word is negated if it is rated (it is not meaningful to do otherwise)
if token._.valence:
for c in token.children:
# if the token is modified by a negation
if c.dep_ == "advmod" and c._.is_negation:
return c
# or if its head it negated:
for c in token.head.children:
if c.dep_ == "advmod" and c._.is_negation:
return c
Token.set_extension("is_negated", getter=is_negated, force=True)
for t in doc:
print(t, "\t", t._.valence, t._.is_negation, "-", t._.is_negated)
Jag 0.0 False - None
är 0.0 False - None
inte 0.0 True - None
glad 3.1 False - inte
men 0.0 False - None
jag 0.0 False - None
skulle 0.0 False - None
inte 0.0 True - None
säga 0.0 False - None
att 0.0 False - None
jag 0.0 False - None
är 0.0 False - None
ledsen -2.1 False - inte
. 0.0 False - None
asent.visualize(doc)
doc[-2]._.polarity
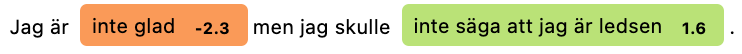
TokenPolarityOutput(polarity=1.554, token=ledsen, span=inte säga att jag är ledsen)
Exercise
You will notice that there is no contrastive conjugation for
Swedish, but that the part-of-speech tags do include a tag for it
(CCONJ). Overwrite the is_contrastive_conj extension to include
contrastive conjugations.