Getting started#
![]()
Asent is a package for fast and transparent sentiment analysis. The package applied uses a dictionary of words rated as either positive or negative and a series of rules to determine whether a word, sentence or a document is positive or negative. The current rules account for negations (i.e. “not happy”), intensifiers (“very happy”) and account for contrastive conjugations (i.e. “but”) as well as other emphasis markers such as exclamation marks, casing and question marks. The following will take you through how the sentiment is calculated in a step by step fashion.
To start of with we will need a spaCy pipeline as well as we will need to add the asent pipeline to it.
For English we can add the asent_en_v1 to it, where en indicates that it is the English pipeline and v1 indicate
that it is version 1.
import asent
import spacy
# load spacy pipeline
nlp = spacy.load("en_core_web_lg")
# add the rule-based sentiment model
nlp.add_pipe("asent_en_v1")
Note
You will need to install the spaCy pipeline beforehand it can be installed using the following command:
python -m spacy download en_core_web_lg
For Danish we can add the asent_da_v1 to it, where da indicates that it is the Danish pipeline and v1 indicate
that it is version 1.
import asent
import spacy
# load spacy pipeline
nlp = spacy.load("da_core_news_lg")
# add the rule-based sentiment model
nlp.add_pipe("asent_da_v1")
Note
You will need to install the spaCy pipeline beforehand it can be installed using the following command:
python -m spacy download da_core_news_lg
For Norwegian we can add the asent_no_v1 to it, where no indicates that it is the Norwegian pipeline and v1 indicate
that it is version 1.
import asent
import spacy
# load spacy pipeline
nlp = spacy.load("nb_core_news_lg")
# add the rule-based sentiment model
nlp.add_pipe("asent_no_v1")
Note
You will need to install the spaCy pipeline beforehand it can be installed using the following command:
python -m spacy download nb_core_news_lg
For Swedish we can add the asent_se_v1 to it, where se indicates that it is the Swedish pipeline and v1 indicate
that it is version 1.
import asent
import spacy
# load spacy pipeline
nlp = spacy.load("sv_core_news_sm")
# add the rule-based sentiment model
nlp.add_pipe("asent_sv_v1")
Token valence and polarity#
As seen in the following. token valence is simply the value gained from a lookup in a rated dictionary. For instance if the have the example sentence “I am not very happy” the word “happy”` have a positive human rating of 2.7 which is not amplified by the word being in all-caps.
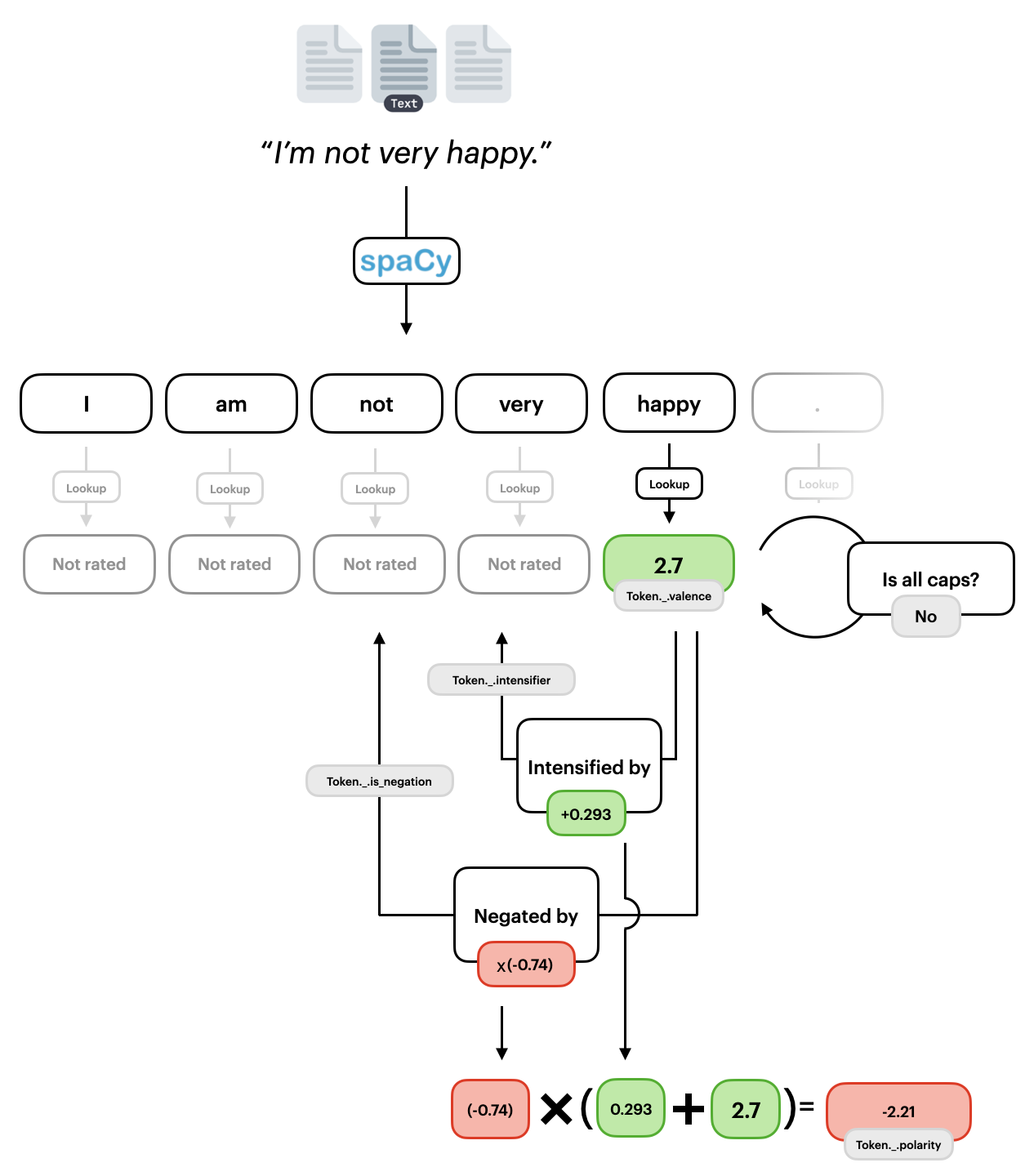
We can extract valence quite easily using the valence extension:
doc = nlp("I am not very happy.")
for token in doc:
print(token, "\t", token._.valence)
I 0.0
am 0.0
not 0.0
very 0.0
happy 2.7
. 0.0
See also
Want to know more about the where these rated dictionaries come from? Check Languages to see the lexical resources used for each language.
Naturally, in this context happy should not be perceived positively as it is negated, thus we should look at token polarity. Token polarity examines if a word is negated and it so multiplies the values by a negative constant. This constant is emperically derived to be 0.74 (Hutto and Gilbert, 2014). Similarly, with the specific example we chose we can also see that “happy”` is intensified by the word “very”, while increases it polarity. The constant 0.293 is similarly emperically derived by Hutto and Gilbert. We can similarly extract the polarity using the polarity extension:
for token in doc:
print(token._.polarity)
polarity=0.0 token=I span=I
polarity=0.0 token=am span=am
polarity=0.0 token=not span=not
polarity=0.0 token=very span=very
polarity=-2.215 token=happy span=not very happy
polarity=0.0 token=. span=.
Notice that here we even get further information, that token “happy”, has a polarity of -2.215 and that this includes the span (sequence of tokens) “not very happy”.
Visualizing polarity#
Asent also includes a series of methods to visualize the token polarity:
doc = nlp("I am not very happy, but aslo not very especially sad")
asent.visualize(doc, style="prediction")

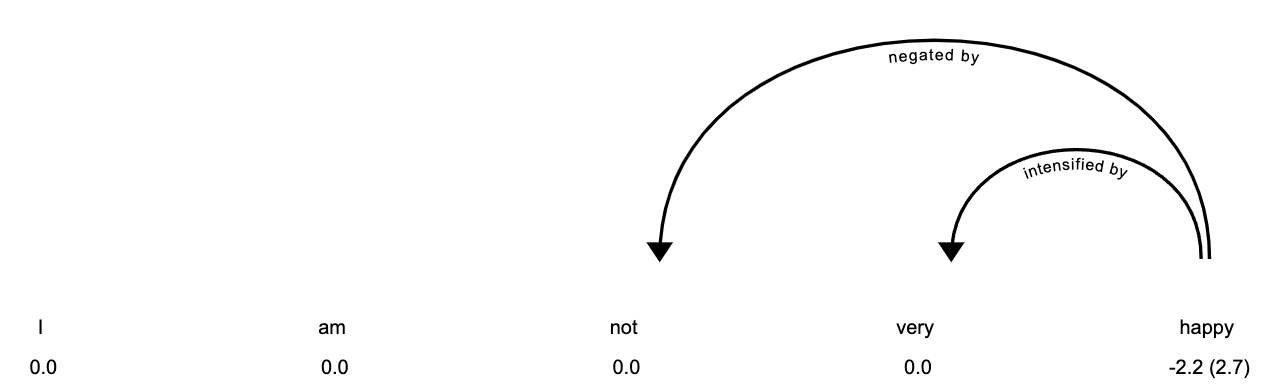
You can even get more information about why the token has the polarity by plotting the model analysis:
asent.visualize(doc[:5], style="analysis")
Document and Span Polarity#
We want to do more than simply calculate the polarity of the token, we want to extract information about the entire sentence (span) and aggregate this across the entire document.
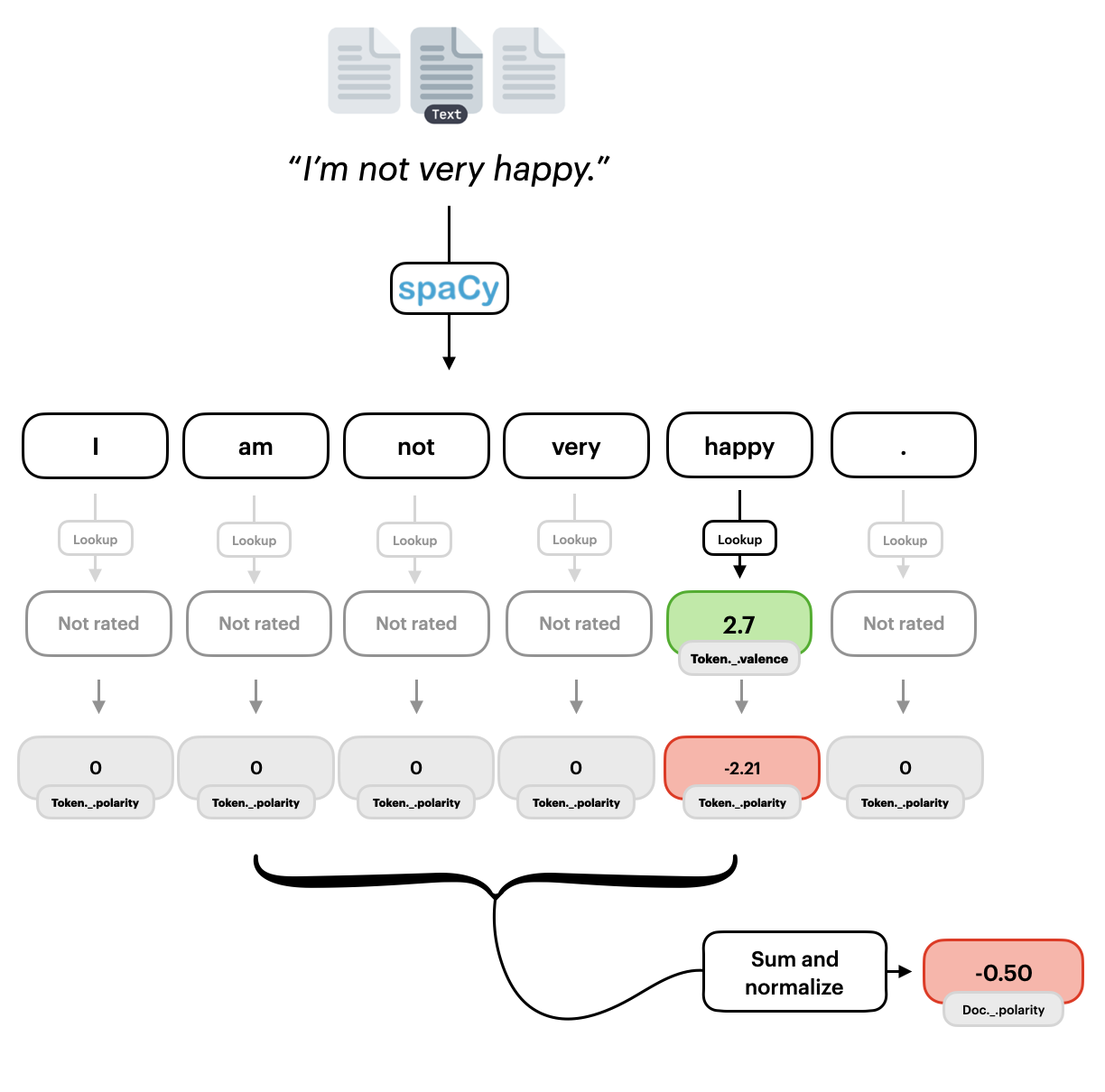
The calculation of the sentence polarity includes a couple of steps. First, it checks if the sentence contains a contrastive conjugation (e.g. “but”), then overweight words after the but and underweight previous elements. This seems quite natural for example the sentence “The movie was great, but the acting was horrible”, noticeably put more weight on the second statement. This has also been shown empirically by (Hutto and Gilbert, 2014). Afterwards, the model takes into account question marks and exclamation marks, which both increases the polarity of the sentence with negative sentences becoming more negative and positive sentences becoming more positive. Lastly, the polarity is normalized between approximately -1 and 1.
You can easily extract the sentence polarity and the document polarity using:
doc = nlp("I am not very happy.")
for sentence in doc.sents:
print(sentence._.polarity)
neg=0.391 neu=0.609 pos=0.0 compound=-0.4964 span=I am not very happy.
Here we see the normalized score for both the compound, or aggregated, polarity as well
the the neutral neu, negative neg, and positive pos.
Processing mulitple Sentences#
So far we have only looked at a singular sentence. However most documents contain multiple sentences. Here asent treats each sentence as a separate and then aggregates the polarity across all sentences. This also means that checks for contrastive conjugations and negations are only done within the sentence. This is illustrated in the following figure:
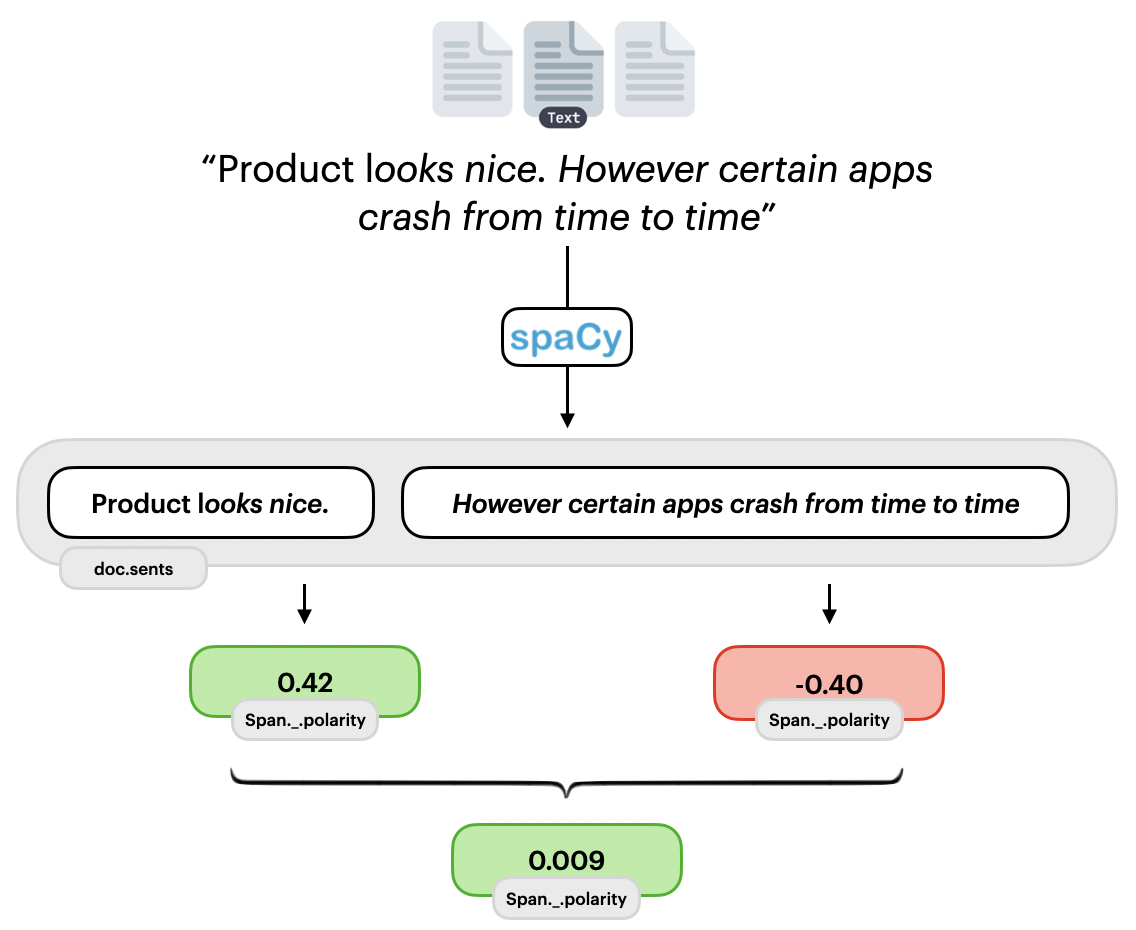
We can examine this by looking at the polarity of a document:
doc = nlp("I am not very happy. I am not very sad.")
print(doc._.polarity)
and comparing it to the polarity of the individual sentences:
neg=0.139 neu=0.619 pos=0.241 compound=0.0098 n_sentences=2
for sentence in doc.sents:
print(sentence._.polarity)
neg=0.0 neu=0.517 pos=0.483 compound=0.4215 span=Product looks nice.
neg=0.278 neu=0.722 pos=0.0 compound=-0.4019 span=However some apps crash from time to time
or we can visualize it:
asent.visualize(doc, style="sentence-prediction")
